
WWDC 2025: The Future is Now (and it Looks a Lot Like AI and a Unified Apple Ecosystem)
The dust has settled on Apple’s Worldwide Developers Conference 2025, and as always, the tech world is abuzz with analysis, predictions, and a healthy dose
The dust has settled on Apple’s Worldwide Developers Conference 2025, and as always, the tech world is abuzz with analysis, predictions, and a healthy dose
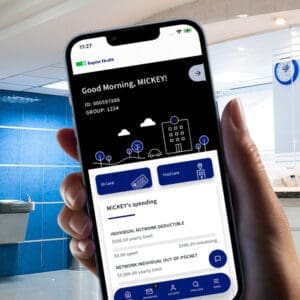
Accessing, Managing, & Navigating Benefits with Ease WebTPA All-Encompassing Simplified User Experience Patient Journey Despite the importance of health insurance in accessing healthcare, there is

In today’s hyper-connected world, cybersecurity isn’t just a technical concern—it’s a business imperative. As AI advances accelerate and development cycles shrink, organizations face a critical

Let’s talk about AI—everyone is. We’re constantly surrounded by articles and surveys with convincing stats like “77% of businesses are using AI today,” and it

Step into the future of hospitality, where AI is the invisible host helping restaurants channel the charm of your favorite local spot—warm welcomes, personalized touches, and zero wait time.

Behind every seamless launch and thriving roadmap is a project manager balancing creative chaos, client needs, and executional excellence. They’re part strategist, part therapist, part time wizard—and entirely essential.

A strong product analytics strategy is built on precision—but getting started doesn’t have to be overwhelming. This guide walks you through a minimum viable product (MVP) approach to analytics, helping you define key roles, set measurable goals, and implement a streamlined tracking plan that evolves with your business.

Ditch the tedious spreadsheets and streamline your analytics tracking plan with AI. This guide walks you through using Gemini and Bottle Rocket’s measurement plan template to quickly generate a comprehensive tracking plan for new or existing digital products—ensuring smarter, data-driven decisions without the manual effort.

Strong analytics start with detailed user stories. This guide provides a structured template and AI-powered approach to quickly generate analytics-focused user stories—helping product teams create clear, actionable tracking events for smarter data collection and seamless implementation.

In today’s competitive restaurant landscape, where diners
increasingly expect personalized and frictionless digital
experiences, the quality of a restaurant’s mobile app can be a
decisive factor in its market success. While many restaurants
are still settling for off-the-shelf solutions, industry leaders are
discovering the secret sauce of custom digital experiences

Retrieval-Augmented Generation (RAG) is an advanced AI framework that enhances text generation by integrating external knowledge retrieval with generative models.

Generative AI tools like ChatGPT are powerful, but getting the best results requires skillful prompt engineering. Tyler Milner, Architect at Bottle Rocket, shares 10 essential tips to optimize your interactions. Don’t let AI guess, use these strategies to encourage clarification and missing details.

MACH enables businesses to build modular digital environments, allowing each component to operate independently.

The future of AI-assisted development is bright, and it should not be seen as a threat to engineers but as a benefit that could transform the speed and quality at which we’re able to innovate and produce new ideas across every industry.

Advances in managing everything from transportation to waste management promise to have a significant impact on residents and businesses, improving everyone’s overall quality of life.

This healthcare technology stack is a comprehensive digital ecosystem designed to support the complex operations of modern healthcare organizations. It is a multi-layered technology framework that integrates various systems and platforms to create a cohesive digital infrastructure for healthcare operations.

Multi-Modal and Multi-Model Compared Introduction Large Language Model (LLM) Applications have revolutionized the way humans interact with machines, enabling seamless communication and collaboration across various

Have you ever felt overwhelmed by the task of setting up an efficient automation framework for your QA tests? Have you struggled with maintaining tests

You can use Flutter to build apps for MacOS to provide a desktop experience for your users.

The IoT has already made a big impact in both industrial and consumer marketplaces via a variety of technologies, ranging from predictive maintenance systems in factories to connected appliances in kitchens.

Multiple studies and opinion surveys performed across industries agree: It’s more cost-effective to retain existing customers than it is to acquire new ones.

With Ai, duplicative testing and imaging decreases, and the accuracy of diagnosis increases.

Mobile apps provide users with a variety of services and entertainment, 24/7, via the powerful, portable computers many of us carry everywhere—our smartphones and tablets.

Apple clearly wanted this to be a set of glasses instead of having to rely on cameras — and I see why that’s the case.

Embracing API Design-First is essential to unlocking the full potential of your software development teams and enabling seamless digital experiences to be delivered to customers.
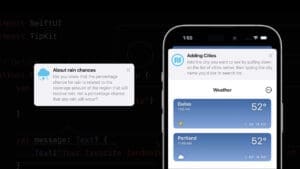
Often we believe that the best mobile experiences are ones where the user needs no assistance or introduction to their use.

The technology streamlines service by providing on-demand attention, accessibility, and personalization to guests.

Companies are taking
advantage of the down turn period to get their ship in order. This involves concentrating on customer value and making sure they aren’t wasting money by optimizing current tech investments.

Bottle Rocket, a leading mobile app development company, today announced its selection as a Partner in Google’s esteemed Flutter Consultants program.

“Innovation” is a guiding principle among tech teams, and that doesn’t just apply to the products they create for the marketplace.
We’re in the business of crafting sleek designs, generating innovative ideas, developing experiences that are dead simple to use. We design people-first experiences that launch your business further.

Let’s look at the top three platforms and what makes them unique: iOS, Android, and Flutter At Bottle Rocket, we pride ourselves on knowing the

Xamarin is a popular cross-platform mobile app development framework that has been widely used by C# developers and organizations to write applications for Android and iOS platforms. However, as most know, Xamarin is quickly approaching its end of life on May 1, 2024.

As digital transformation becomes a leading initiative across industries, businesses are onboarding and using more and more applications—leading, in many cases, to more and more application programming interfaces.

SOC 2 Type 1 Certification is one of the most comprehensive security assessments, highlighting Bottle Rocket’s commitment to data security and privacy.

How telehealth and artificial intelligence will dominate in a new era of health care

Let’s review the device’s capabilities and what we might be able to expect after the device launches next year.

There’s a lot of excitement prior to a large-scale tech product launch or update, as devs look forward to seeing all their hard work in action and users anticipate the new benefits and/or experience.

There are tools and processes that companies with remote workforces can provide that can help their team members troubleshoot and solve many problems on their own

Non-tech leaders may latch on to a frequently discussed tech “buzzword” or concept and believe their organization needs to “add it” or “do something with it”.

One of the first steps to analyzing which systems you should invest in is to do some analysis of which systems your employees and customers are using.


